目录
- 一、作业执行容错
- 1.1、Task Failover策略
- 1.2、Job Restart策略
- 二、守护进程容错
- 2.1、TaskManager 的容错
- 2.2、ResourceManager 的容错
- 2.3、JobMaster 的容错
- 2.4、并发故障
- 三、总结
一、作业执行容错Flink 的错误恢复机制分为多个级别,即 Execution 级别的 Failover 策略和 ExecutionGraph 级别的 Job Restart 策略 。当出现错误时,Flink 会先尝试触发范围小的错误恢复机制,如果仍处理不了才会升级为更大范围的错误恢复机制,具体可以看下面的序列图 。
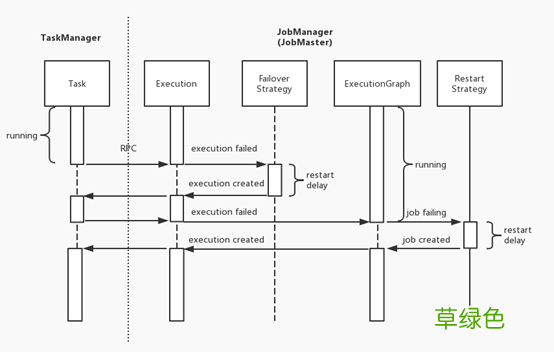
文章插图
当 Task 发生错误,TaskManager 会通过 RPC 通知 JobManager,后者将对应 Execution 的状态转为 failed 并触发 Failover 策略 。如果符合 Failover 策略,JobManager 会重启 Execution,否则升级为 ExecutionGraph 的失败 。ExecutionGraph 失败则进入 failing 的状态,由 Restart 策略决定其重启(restarting 状态)还是异常退出(failed 状态) 。
1.1、Task Failover策略Task Failover策略目前有三个,分别是:RestartAll、RestartIndividualStrategy 和 RestartPipelinedRegionStrategy 。
RestartAll: 重启全部 Task,是恢复作业一致性的最安全策略,会在其他 Failover 策略失败时作为保底策略使用 。目前是默认的 Task Failover 策略 。
RestartPipelinedRegionStrategy: 重启错误 Task 所在 Region 的全部 Task 。Task Region 是由 Task 的数据传输决定的,有数据传输的 Task 会被放在同一个 Region,而不同 Region 之间没有数据交换 。
RestartIndividualStrategy: 恢复单个 Task 。因为如果该 Task 没有包含数据源,这会导致它不能重流数据而导致一部分数据丢失 。考虑到至少提供准确一次的投递语义,这个策略的使用范围比较有限,只应用于 Task 间没有数据传输的作业 。
1.2、Job Restart策略如果 Task 错误最终触发了 Full Restart,此时 Job Restart 策略将会控制是否需要恢复作业 。Flink 提供三种 Job 具体的 Restart Strategy 。
FixedDelayRestartStrategy: 允许指定次数内的 Execution 失败,如果超过该次数则导致 Job 失败 。FixedDelayRestartStrategy 重启可以设置一定的延迟,以减少频繁重试对外部系统带来的负载和不必要的错误日志 。
FailureRateRestartStrategy: 允许在指定时间窗口内的指定次数内的 Execution 失败,如果超过这个频率则导致 Job 失败 。同样地,FailureRateRestartStrategy 也可以设置一定的重启延迟 。
NoRestartStrategy: 在 Execution 失败时直接让 Job 失败 。
二、守护进程容错Flink on YARN 的部署模式,关键的守护进程有 JobManager 和 TaskManager 两个,其中JobManager的主要职责协调资源和管理作业的执行分别为ResourceManager 和 JobMaster 两个守护线程承担,三者之间的关系如下图所示 。
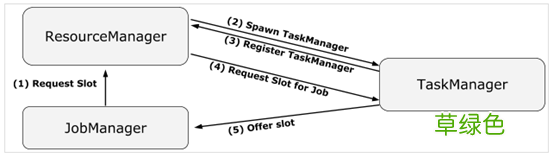
文章插图
2.1、TaskManager 的容错如果 ResouceManager 通过心跳超时检测到或者通过集群管理器的通知了解到 TaskManager 故障,它会通知对应的 JobMaster 并启动一个新的 TaskManager 以做代替 。注意 ResouceManager 并不关心 Flink 作业的情况,这是 JobMaster 的职责去管理 Flink 作业要做何种反应 。
如果 JobMaster 通过 ResouceManager 的通知了解到或者通过心跳超时检测到 TaskManager 故障,它首先会从自己的 slot pool 中移除该 TaskManager,并将该 TaskManager 上运行的所有 Tasks 标记为失败,从而触发 Flink 作业执行的容错机制以恢复作业 。
TaskManager 的状态已经写入 checkpoint 并会在重启后自动恢复,因此不会造成数据不一致的问题 。
2.2、ResourceManager 的容错如果TaskManager通过心跳超时检测到 ResourceManager 故障,或者收到 zookeeper 的关于ResourceManager失去leadership通知,TaskManager会寻找新的 leader,ResourceManager 并将自己重启注册到其上,期间并不会中断 Task的执行 。
如果JobMaster通过心跳超时检测到ResourceManager故障,或者收到 zookeeper 的关于 ResourceManager 失去 leadership 通知,JobMaster 同样会等待新的 ResourceManager 变成 leader,然后重新请求所有的TaskManager 。考虑到 TaskManager 也可能成功恢复,这样的话 JobMaster 新请求的 TaskManager 会在空闲一段时间后被释放 。
ResourceManager上保持了很多状态信息,包括活跃的 container、可用的 TaskManager、TaskManager 和 JobMaster 的映射关系等等信息,不过这些信息并不是 ground truth,可以从与 JobMaster 及 TaskManager 的状态同步中再重新获得,所以这些信息并不需要持久化 。
2.3、JobMaster 的容错如果 TaskManager 通过心跳超时检测到 JobMaster 故障,或者收到 zookeeper 的关于 JobMaster 失去 leadership 通知,TaskManager 会触发自己的错误恢复,然后等待新的 JobMaster 。如果新的 JobMaster 在一定时间后仍未出现,TaskManager 会将其 slot 标记为空闲并告知 ResourceManager 。
如果 ResourceManager 通过心跳超时检测到 JobMaster 故障,或者收到 zookeeper 的关于 JobMaster 失去 leadership 通知,ResourceManager 会将其告知 TaskManager,其他不作处理 。
JobMaster 保存了很多对作业执行至关重要的状态,其中 JobGraph 和用户代码会重新从 HDFS 等持久化存储中获取,checkpoint 信息会从 zookeeper 获得,Task 的执行信息可以不恢复因为整个作业会重新调度,而持有的 slot 则从 ResourceManager 的 TaskManager 的同步信息中恢复 。
2.4、并发故障Flink on YARN 部署模式下,因为 JobMaster 和 ResourceManager 都在 JobManager 进程内,如果JobManager 进程出问题,通常是 JobMaster 和 ResourceManager 并发故障,那么 TaskManager 会按以下步骤处理:
- 按照普通的 JobMaster 故障处理 。
- 在一段时间内不断尝试将 slot 提供给新的 JobMaster 。
- 不断尝试将自己注册到 ResourceManager 上 。
三、总结Flink 容错机制确保了 Flink 的可靠性和持久性,具体来说它包括作业执行的容错和守护进程的容错两个方面 。在作业执行容错方面,Flink 提供 Task 级别的 Failover 策略和 Job 级别的 Restart 策略来进行故障情况下的自动重试 。在守护进程的容错方面,在on YARN 模式下,Flink 通过内部组件的心跳和 YARN 的监控进行故障检测 。TaskManager 的故障会通过申请新的 TaskManager 并重启 Task 或 Job 来恢复,JobManager 的故障会通过集群管理器的自动拉起新 JobManager 和 TaskManager 的重新注册到新 leader JobManager 来恢复 。
【浅谈Flink容错机制之作业执行和守护进程】以上就是浅谈Flink容错机制之作业执行和守护进程的详细内容,更多关于Flink容错机制 作业执行和守护进程的资料请关注考高分网其它相关文章!
- 春季老年人吃什么养肝?土豆、米饭换着吃
- 三八妇女节节日祝福分享 三八妇女节节日语录
- 老人谨慎!选好你的“第三只脚”
- 校方进行了深刻的反思 青岛一大学生坠亡校方整改校规
- 脸皮厚的人长寿!有这特征的老人最长寿
- 长寿秘诀:记住这10大妙招 100%增寿
- 春季老年人心血管病高发 3条保命要诀
- 眼睛花不花要看四十八 老年人怎样延缓老花眼
- 香槟然能防治老年痴呆症? 一天三杯它人到90不痴呆
- 老人手抖的原因 为什么老人手会抖